Testing Qwen3-Coder-Next
Are local models useful for coding on a normal PC? Let’s find out.
Using llmfit
A good first step is using llmfit to figure out what some good options are:
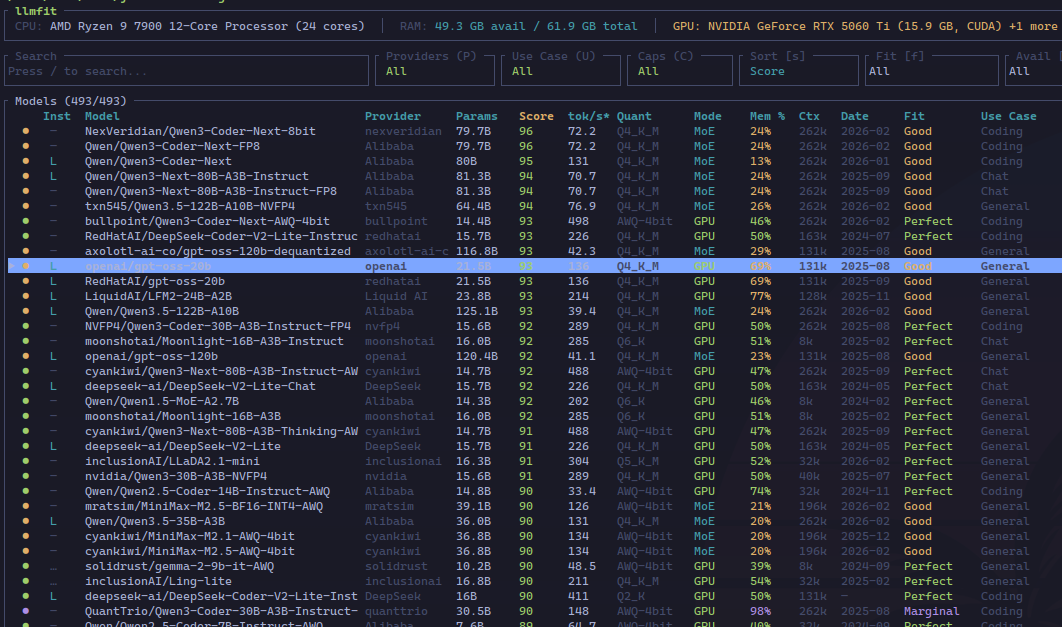
The Inst column shows if the model is supported (-), if it is available (✓), if it is available through llama.cpp (L), Ollama (O), … Most of the data shown is scraped from the web, but for some models, it is calculated based on a few heuristics. This explains the difference between Qwen3-Coder-Next and Qwen3-Coder-Next-FP8. These two are the same model, with the -FP8 version already quantized to 8 bits.
But the way llmfit works is searching for the optimal quantized model (for example, from Unsloth) and calculating the scores from there. The differences then come from the fact that it uses the scraped data for Qwen3-Coder-Next, but for Qwen3-Coder-Next-FP8 it infers some params.
For example, these models (or model, because they are both the same) use a MoE architecture, where instead of a big FFN, we have several different small FFNs. According to the HF card, Qwen3-Coder-Next (and the FP8 variant) has 512 experts, of which only 10 are activated at the same time, with one additional shared expert. Each expert has a hidden layer of 512 dimensions.
So the main difference is in the number of active parameters, that is, the number of params for the active experts: for Qwen3-Coder-Next we have the 3B set in the HF card, but for Qwen3-Coder-Next-FP8 we have almost 5.5B. So this would make a better use of the GPU, while also leaving more RAM free. Maybe even allowing a better quantization.
Downloading the model
In any case, this is all wrong: there is only one model to quantize, and the FP8 (80GB) version wouldn’t fit in my RAM + VRAM.
So I’m going to download this one:
1
hf download unsloth/Qwen3-Coder-Next-GGUF --include "Qwen3-Coder-Next-UD-Q4_K_XL.gguf" --local-dir ./models/Qwen3-Coder-Next
The UD-Q4_K_XL quantization is a special unsloth dynamic quantization that is supposed to perform better.
Testing the model
Once downloaded, we run it with llama.cpp:
1
llama-server -m ./models/Qwen3-Coder-Next/Qwen3-Coder-Next-UD-Q4_K_XL.gguf
The code generated is in this file. Qwen also added these comments:
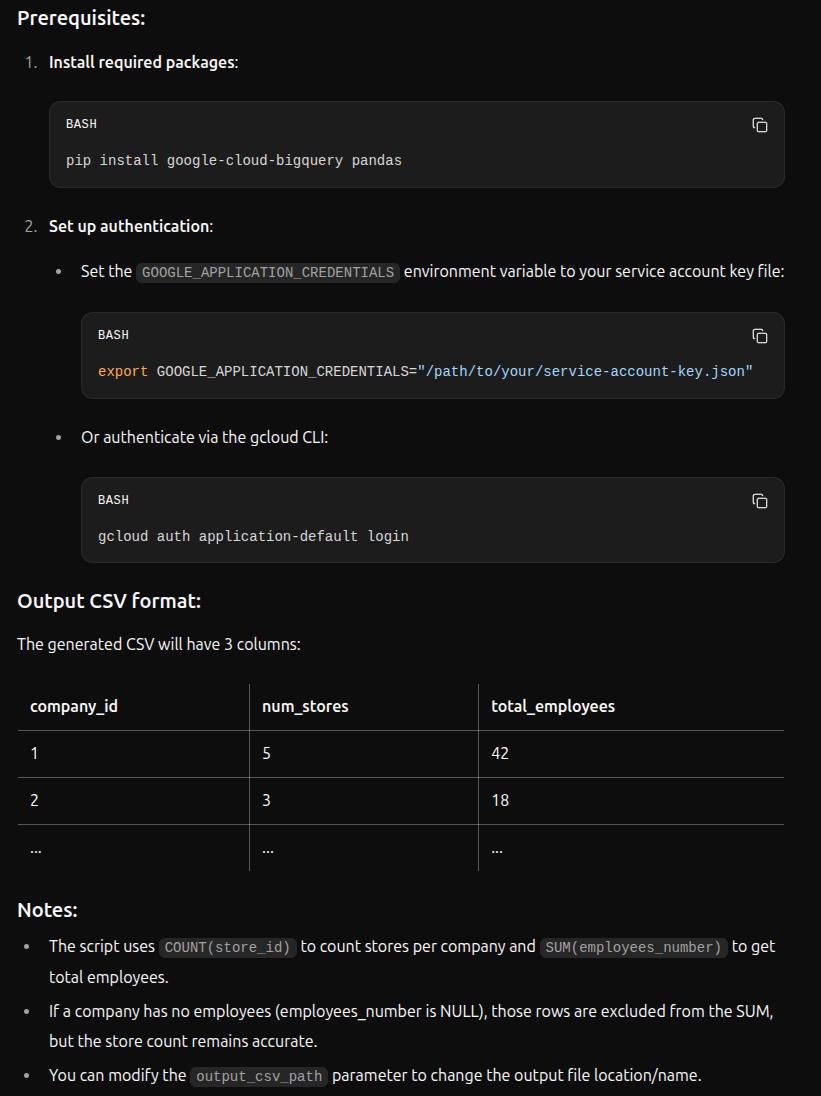
The result isn’t bad: there are things to improve (project in FROM clause, location, no real reason for the ORDER BY), but the code works.
I will try something more complex when I have time.