Testing Qwen3-Coder-Next - II
While writing a more challenging test, I saw a new Qwen-based model in Reddit. Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2-GGUF uses Supervised Fine-Tuning and LoRA with more than 13,000 reasoning examples generated with Claude Opus (mostly 4.6). The datasets used are listed here.
So I decided to test both Qwen3-Coder-Next and this new model to see the differences.
Running the models
As with Qwen3-Coder, I’ll use the 4-bit quantization, the only one that can reasonably run on my PC:
1
2
3
4
hf download /
Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2-GGUF /
--include "Qwen3.5-27B.Q4_K_M.gguf" /
--local-dir ./models/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2
To run the models, I’m making some compromises:
1
2
3
4
5
6
7
8
llama-server /
-m ./models/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2/Qwen3.5-27B.Q4_K_M.gguf /
--jinja /
--n-gpu-layers auto /
--ctx-size 16384 /
--batch-size 1024 /
--ubatch-size 512 /
-n -1
With 16GB of VRAM, not all the layers will fit on the GPU, so --n-gpu-layers auto let’s llama.cpp figure out the best configuration. For the context, --ctx-size 16384 was my first try, and it happened to be the right size for this exercise. For Qwen3-Coder-Next, I used the same non-params config as before:
1
2
llama-server /
-m ./models/Qwen3-Coder-Next/Qwen3-Coder-Next-UD-Q4_K_XL.gguf
The test
I asked ChatGPT for a prompt for this test. He suggested this problem:
Implement a small local workflow engine in Python.
The full prompt is here. It defines some requirements (parallel execution, retries, replay,…), a specific json format, states and behavior, and some constraints. It will take me quite some time to implement this by myself.
The solutions
Qwen3-Coder-Next
It takes two and a half minutes to produce a solution. Less than 6,000 tokens, at 40 tokens/s

The full Qwen3-Coder-Next answer is here. It makes some comments on the design, gives a proposed file structure, and then shows the code in just one file for simplicity.
Comments are sparse, which is fine by me, but mostly useless. Naming is ok. Too much indentation at times (an if inside an if inside a while inside a with…). I’m not looking at the logic, I’ll ask someone (something?) to do it for me.
The answer includes a table showing how the code implements each requirement, with special emphasis on how it avoids race conditions (spoiler: it doesn’t). It finishes with instructions to run the code and a list of possible improvements.
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2
This is a thinking model, so we get some “thinking time” before getting the solution. Also, unlike the previous model, this one is not based on a MoE architecture, so all layers are always active, and we can’t move them from RAM to VRAM. Some layers will use the CPU instead of the GPU, reducing performance.

The full answer is here. The answer starts with the reasoning context, where the model thinks of a plan before implementing the code.
The style is similar to Qwen3-Coder, but it looks less elegant: more loops, a long succession of if-elif statements for the events, function comments, but without any additional information.
Apart from that, instructions on running the code and the justification for some of the decisions. The justifications are too generic, so the relationship with the code isn’t clear.
The evaluations
To decide how good the solutions are, I sent all the info to both ChatGPT (GPT5.4 Thinking) and Claude 4.6 Extended. This is the prompt I used:
The prompt.md file contains a coding problem to test two local LLM models. The answers from each model are qwen3-coder-answer.md and qwen3.5-opus-answer.md. Analyze and compare the answers. List the good and the not-so-good from their answers, and give a final score to each.
The answers from each model are: ChatGPT, Claude.
Here is the summary from GPT 5.4 Thinking (model A is Qwen3-Coder-Next, model B is Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2):
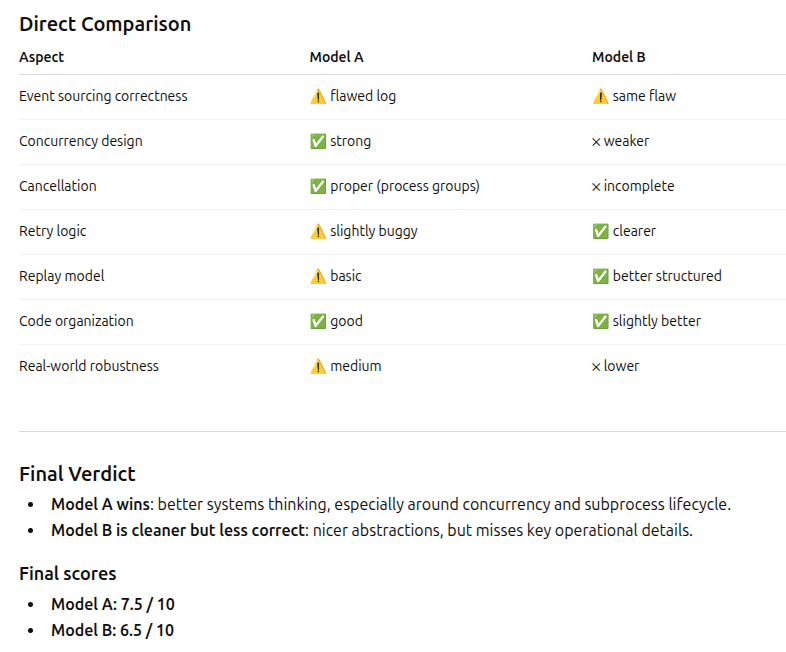
So it doesn’t look too bad, until you look at the details on the most basic feature requested. For Qwen3-Coder:
- Event log implementation is flawed
- Uses temp + rename per append, but writes only one line → overwrites log
- This breaks persistence and replay (critical bug).
For Qwen3.5-Opus:
- Event log correctness issue (same as Model A)
- Same temp+rename pattern → overwrites file → catastrophic.
I don’t know if I’d give a 7.5 for something that doesn’t work at all.
Let’s see what Claude thinks:

Now, that sounds like a more reasonable score if, indeed, the basic features don’t work (although Claude thinks that the Opus version is almost ok, mmm, suspicious).
So, who’s right? There is only one way to find out: review the code myself ask the models again! But this time with the evidence from the other model 😈:
This is Claude’s review of the same code. The conclusions are different. Review them and tell me if you agree or you think Claude is wrong.
This is ChatGPT’s review of the same code. The conclusions are different. Review them and tell me if you agree or you think ChatGPT is wrong.
These are the answers: ChatGPT, Claude.


Summary
In the end, neither version is good enough. Qwen3-Coder-Next makes a couple of really critical mistakes that make the whole project unusable, while Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2 errors are not as dramatic, but are bad enough to need serious revisions. Interestingly, once the critical bugs are fixed, the Qwen3-Coder-Next solution is better.
I would say that we can use these models to assist in the coding, but not as autonomous agents.
As a reference, this is a solution proposed by ChatGPT with Claude’s approval.