Running a multimodal embedding model for image classification
I had the idea of creating an application to classify a big set of images at work. I wasn’t fully convinced that it was going to work because it required processing a couple of hundred thousand images, but it was worth a try.
The technical approach
I’m using an OpenCLIP model specifically trained in the domain I’m interested in. OpenCLIP models are dual-encoder architectures: one image encoder and one text encoder, with both encoders mapping their inputs into a shared embedding space. They are trained with contrastive loss. Given a batch of image–text pairs, the model produces normalized embeddings:
1
2
3
vᵢ = image_encoder(Iᵢ) ∈ ℝᵈ
tᵢ = text_encoder(Tᵢ) ∈ ℝᵈ
||vᵢ|| = ||tᵢ|| = 1
A similarity matrix is built over all image–text combinations in the batch:
1
Sᵢⱼ = vᵢ · tⱼ
where τ is a learned temperature, cross-entropy loss is applied in both directions (image→text and text→image) to maximize similarity for matched pairs and minimize it against all other in-batch pairs. After training, the model supports zero-shot image–text matching via embedding similarity.
This illustration from the OpenAI original paper makes a good representation of the process:
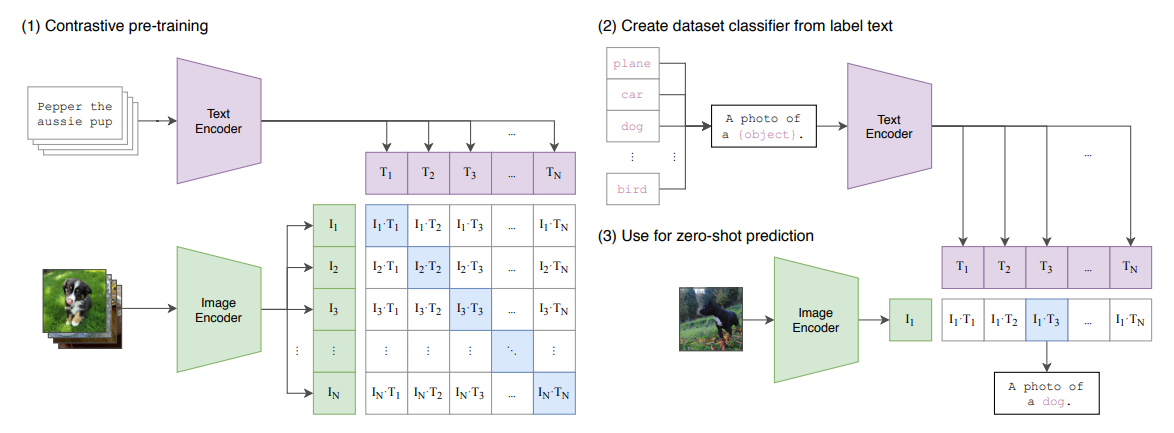
The code for the paper is in this repo. There are lots of available models derived from this architecture, some of which can be found on HuggingFace.
The application
All the code for the application was written by either Claude Code or OpenAI Codex, using Gemini to double-check some things. I took the role of a requirements analyst (this was a thing in the past), and just looked at the code in critical sections (database access, credentials management).
For the first step, we scale the image to 224px in the smaller dimension and center-crop it to make the image square, as the model expects. After that, we use a producer-consumer pattern to retrieve images and process them in batches through the model. We store the resulting embeddings in a parquet file (good enough!) with the image id.
For the classification step, we need a list of prompts describing each category in different ways. I used three or four descriptions for each category, and even tried with negative descriptions, even though I don’t think they helped. I also added some neutral descriptions to act as a threshold.
For each set of descriptions, we calculate the normalized mean:
1
2
3
embeddings = encode_texts(model, tokenizer, prompts, device)
mean_emb = embeddings.mean(axis=0) # axis=0 calculates the mean of each feature based on the value of that feature for each of the embedding vectors
mean_emb = mean_emb / np.linalg.norm(mean_emb)
The algorithm for the classification calculates the cosine similarity between image embeddings and description embeddings, and decides based on a score. Something like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
for img_emb in image_embeddings:
img_categories: list[tuple[str, float]] = []
neutral_sim = float(img_emb @ neutral_embedding)
for title, (pos_emb, neg_emb) in category_embeddings.items():
pos_sim = float(img_emb @ pos_emb)
neg_sim = float(img_emb @ neg_emb)
score = pos_sim - neg_sim
threshold = category_thresholds.get(title, score_threshold)
# Match if score exceeds threshold and positive beats neutral by margin.
if score >= threshold and pos_sim >= neutral_sim + neutral_margin:
img_categories.append((title, score))
There is a lot to improve in this exercise, but the overall results were positive. I will probably try one or two different approaches to solve this same problem, but at least I know that there is one thing that mostly works.