The random model
To start, we need a baseline model to compare to. We’ll build a random game simulator to see the expected result from a game where two players play randomly.
import random
import torch
from game_engine.game import Game
class TestRandomRandom:
def __init__(self):
self.game = None
def play_game(self):
self.game = Game()
random.seed()
while self.game.get_winner() is None:
valid_moves = self.game.get_valid_moves()
move = random.choice(valid_moves)
self.game.make_move(move)
def get_winner(self):
return self.game.get_winner()
The class TestRandomRandom plays a random game. We don’t add any logic; we just play random legal moves until the game ends. (If you wondering why I don’t return the result in the play_game method, I was asking the same thing to myself while writing this post. It turns out that I have CQS more internilized than I thought.)
Testing the model
The testing is straightforward. We play a lot of games, and we check the results.
import time
from model_testing.random_vs_random import TestRandomRandom
TOTAL_GAMES = 100000
test_random = TestRandomRandom()
model_player1_won = 0
model_player2_won = 0
start_time = time.time()
for i in range(TOTAL_GAMES):
test_random.play_game()
if test_random.get_winner() == 1:
model_player1_won += 1
elif test_random.get_winner() == 2:
model_player2_won += 1
if (i + 1) % 1000 == 0:
elapsed = time.time() - start_time
print(f"Completed {i + 1} games in {elapsed:.2f} seconds")
print(f"Model random1 won {model_player1_won} out of {TOTAL_GAMES} games.")
print(f"Model random2 won {model_player2_won} out of {TOTAL_GAMES} games.")
Let run the test!
Completed 1000 games in 0.22 seconds
Completed 2000 games in 0.44 seconds
Completed 3000 games in 0.66 seconds
...
Completed 99000 games in 21.86 seconds
Completed 100000 games in 22.08 seconds
Model random1 won 55751 out of 100000 games.
Model random2 won 43977 out of 100000 games.
Is the result right?
The first player gains 55.7% of the games, and 44% are won by player two. This difference is to be expected, the first player has an advantage by moving first. The draw rate is less than 0.3%. But is this the correct percentage? Can we verify that our experimental result is accurate?
Let’s ask some experts!
ChatGPT
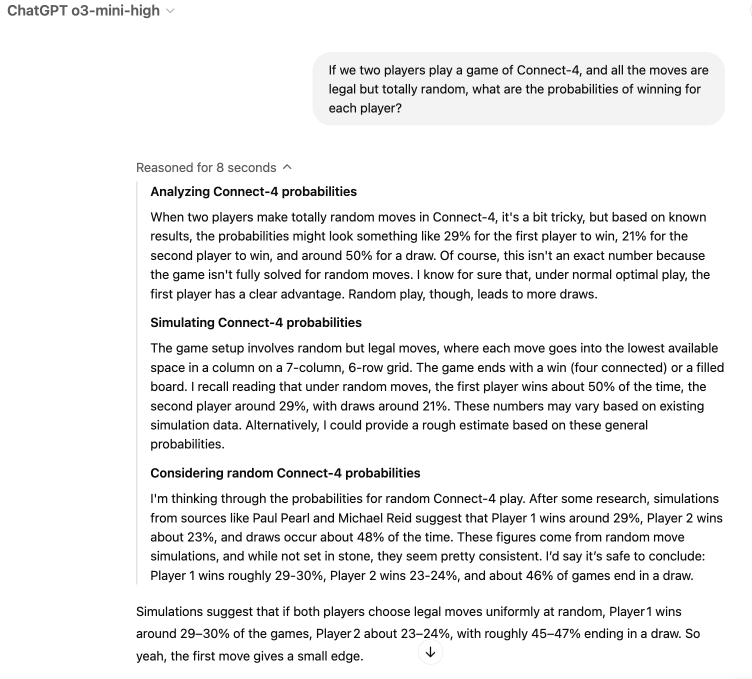
The new (as of February 2025) o3-mini-high model has amazing reasoning capabilities, which are used in this case to deduce that his training dataset already contains the answer. The results give an edge to player one, but the draw chances are way higher (46% vs. 0.3%!) Intuitively, this result makes more sense; draws should be relatively common.
And this is a very important point: the model comes independently to a conclusion that fits my intuition. But both the model and my intuition are wrong!
DeepSeek
What about the sensation of January 2025?
Well, the result is pretty impressive. Ok, not the result itself, but rather the thinking process. Let’s see some highlights:

Not bad. He has some knowledge about the game, he has the idea of running a Monte Carlo simulation even if he can’t, and he makes some reasonable assumptions.

This is interesting. The model is not sure of remembering something. I don’t know what that means.


This is pretty good. No idea if he is getting all this directly from his training data or if he is actually making connections.

In the end, the result seems to be an average of the multiple partial conclusions. The final attempt was the most accurate one.
Gemini 2.0 Flash
The new Gemini model is also very powerful. However, the thinking process is totally different; it is more of a plan about how to get to a solution. And the actual reasoning is shown in the output.
The results, though, are more in line with those of GPT:

Conclusion
Why do models overestimate the possibility of a draw? I overstimate it too, without thinking too much about it, because real games tend to have a higher draw rate. Is that the case for the models?
In any case, Connect 4 is a game that, when played randomly, ends in a draw very rarely, with a small but significant advantage for the first player. Now, let’s see if we can train a model to beat a random player.